Le problème de prédiction optimal
Le point de départ de l’approche stochastique est une distribution de \(n\) prix relatifs entre la période 0 et la période \(t\), le prix relatif du bon \(i\) étant donné par \(p_{it} / p_{i0}\), pour le population (univers) de tous les biens et services \(n\) à mesurer par l’indice des prix. À chaque bien \(i\) est associée la probabilité que \(P_{i}\) observe ce bien transigé sur les deux périodes dans la population de biens mesurée par l’indice, ce qui donne à son tour une mesure de la fréquence d’observation de différentes valeurs pour les changements de prix au fil du temps. Autrement dit, un prix relatif \(p_{t} / p_{0}\) est traité comme une variable aléatoire dans l’approche stochastique, dont la distribution dépend de la distribution sous-jacente des biens et services qui constituent la portée de l’indice des prix.21
Étant donné une distribution des prix relatifs, le meilleur prédicteur d’un changement de prix entre la période 0 et la période \(t\) est la valeur \(I^{A}\) qui minimise l’erreur de prédiction attendue. Formellement, le meilleur prédicteur résout le problème suivant22
\[\begin{align*} \min_{I} E\left[\left(\frac{p_{t}}{p_{0}} - I \right)^{2} \right], \end{align*}\]
où \(E\) est l’opérateur de valeur attendue, repris par la distribution du prix relatif. Comme cela est bien connu, la solution à ce problème consiste à définir \(I^{A} = E(p_{t} / p_{0})\) (Lehmann and Casella 1998, chapitre 1, exemple 7.17); c’est-à-dire que le meilleur prédicteur d’un changement de prix entre deux périodes est le changement attendu de prix. S’il peut sembler inhabituel d’exprimer un indice des prix en termes de valeur attendue, cela souligne simplement qu’un indice des prix est à juste titre une caractéristique de la distribution des prix dans la population. C’est une caractéristique clé de l’approche stochastique, et c’est ce qui permet une analyse significative des propriétés statistiques d’un indice des prix lorsqu’il est calculé avec un échantillon de données sur les prix de la population.
La figure donne un exemple de ce à quoi ressemble le problème de prédiction. Étant donné une distribution des prix relatifs (ligne continue), il y a une erreur de prédiction attendue associée à chaque valeur qu’un indice de prix peut prendre (ligne pointillée). Le meilleur choix pour un indice des prix comme outil de prévision est la valeur qui minimise l’erreur de prédiction attendue (ligne pointillée).
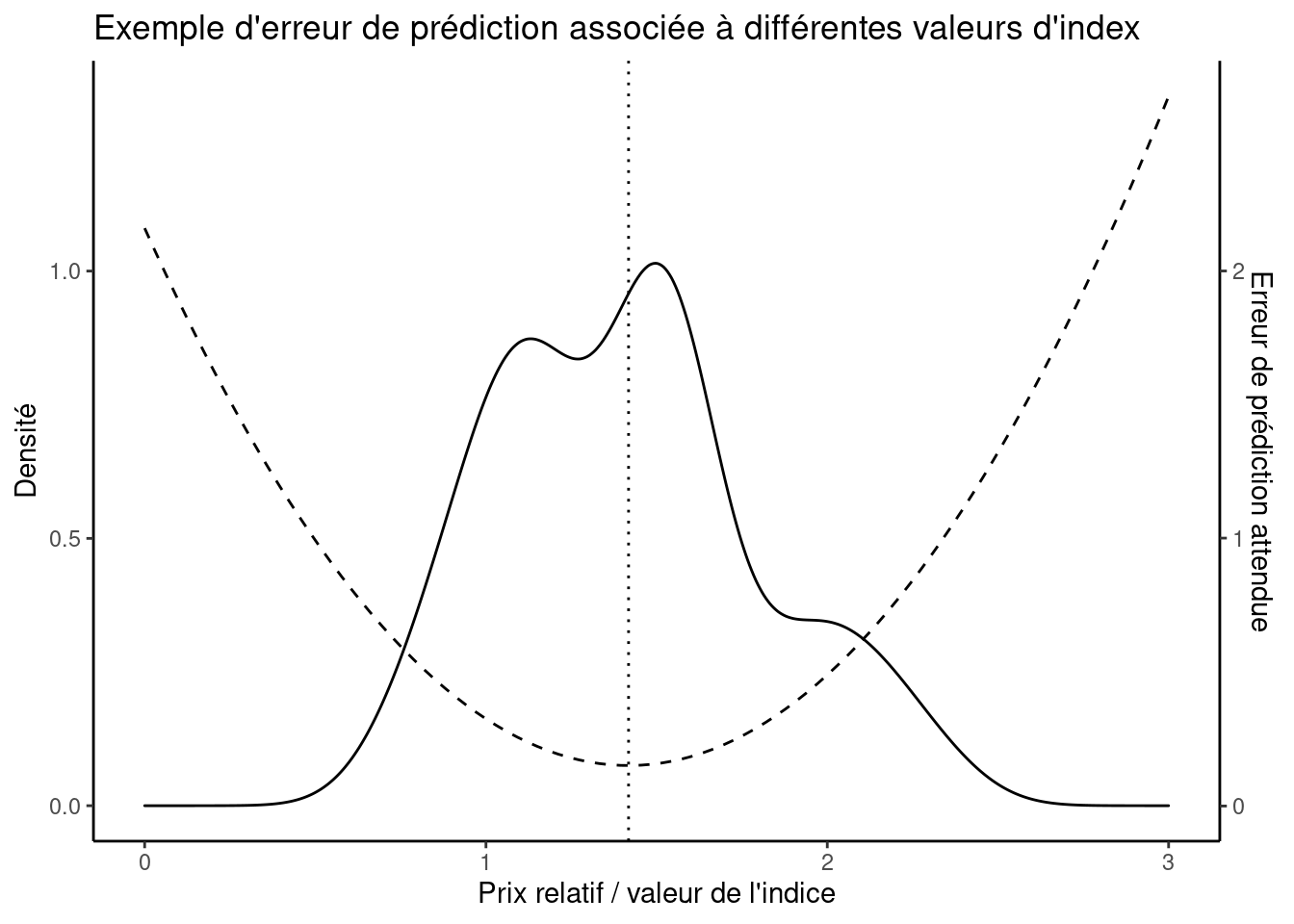
Comme la valeur attendue n’est qu’une moyenne pondérée, l’indice \(I^{A} = E(p_{t} / p_{0})\) est simplement un indice arithmétique qui fait la moyenne des prix relatifs. Ce qui est intéressant, c’est que les poids ont maintenant une nouvelle interprétation — ils sont la probabilité d’observer un bien ou un service transigé dans la population. C’est,
\[\begin{align*} I^{A} = \sum_{i = 1}^{n} \frac{p_{it}}{p_{i0}} P_{i}. \end{align*}\]
Différentes formules arithmétiques d’indice de prix — par exemple, Laspeyres, Paasche, Lowe — correspondent donc à différentes déclarations sur ce qui détermine la probabilité d’observer une transaction. Par exemple, avec un indice de Laspeyres, les probabilités sont données par la part des dépenses ou des revenus de la période 0. Cela revient à dire que la probabilité d’observer une transaction pour un bien est la probabilité de dépenser ou de recevoir un dollar pour ce bien au cours de la période 0.
On a tendance à penser que cette distribution est gaussienne, mais cela signifie que certains biens et services ont des prix négatifs. Dans la plupart des cas, les prix relatifs ne peuvent pas être distribués gaussiens.↩︎
Il s’agit d’un problème de prédiction utilisant une fonction de perte quadratique, pour garantir que l’erreur de prédiction est toujours positive et pour formaliser l’idée qu’une grande erreur de prévision est plus coûteuse que de nombreuses petites erreurs de prévision. Différentes fonctions de perte donnent généralement différents prédicteurs optimaux; par exemple, la fonction de perte absolue renvoie la médiane comme meilleur prédicteur, qui trouve des applications pour les indices des prix des logements. Si les parents de prix sont distribués symétriquement, alors toutes les fonctions de perte convexes symétriques donnent le même indice de prix (Lehmann and Casella 1998, Chapitre 1 Corollaire 7.19).↩︎